Při uložení dat ve sloupcové databázi má tedy každý sloupec svou vlastní datovou strukturu a ukládá se odděleně od ostatních sloupců. Hodnoty jednoho sloupce tak tedy přímo “nesousedí” s hodnotami ostatních sloupců.
Při takovéto struktuře dat je výpočet součtu hodnot v jednotlivých sloupcích mnohem snazší. Dochází totiž k načtení celé tabulky sloupce a získání všech dat která jsou potřebná pro výpočet. Není tedy třeba číst hodnoty ostatních sloupců a ignorovat je, jak by tomu bylo, kdyby se jednalo o řádkovou databázi, kde jsou data uložená po řádcích.
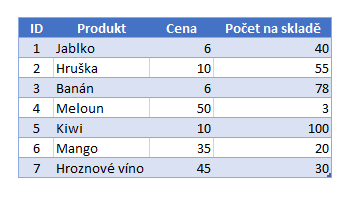
Příkladem takového záznamu v řádkové databázi pro nás mohl být například první řádek [1,“Jablko“,6,40]. V takovém případě bychom museli načíst celý řádek, procházet ho a ignorovat nepotřebné hodnoty jiných sloupců. Při jediném skenování sloupcové databáze získáte pouze užitečná čísla (za celý sloupec) a můžete je rychle agregovat bez nutnosti načítání a ignorování dat z ostatních sloupců.
Příklad získání výsledků ze sloupcové databáze
Kdybychom tedy chtěli znát počet položek na skladě, pak tedy snadno zjistíme, že výsledek je 326. Jak se tento algoritmus ale zachová, když řekneme, že chceme Počet položek na skladě, kde je Cena rovna číslu 10? Počítače takovou úlohu zpravidla řeší tak, že nejprve prohledají sloupec Cena. Tam, kde bude podmínka x = 10 splněna, tam si poznamenají čísla řádků, poté, co získají všechna čísla řádků, tak teprve prohledají sloupec Počet na skladě a sčítají pouze řádky, které si v předchozím kroku identifikovali.
Z toho vyplývá, že čím více omezení na výsledek je z pohledu ostatních sloupců, tím náročnější je získat výsledek. Avšak bez omezení je dosažení výsledku značně jednoduché.
Co krom rychlého čtení hodnot ve sloupci nám tato databáze poskytuje?
Sloupcové databáze mohou být velmi často pomocí komprese smrštěny, čímž dochází ke snížení množství času potřebného pro skenováním dat. A cílem algoritmů komprese VertiPaqu je zmenšit paměťovou stopu vašeho datového modelu.
Jak Vertipaq ukládá hodnoty sloupců do paměti?
Na to není jen jedna odpověď ale hned 3 (aby jich nebylo málo):
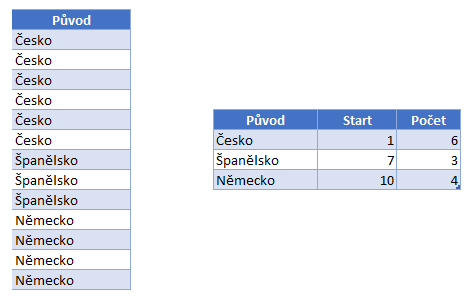
- Kódování hodnot
- Kódování slovníku
- RLE kódování.
Každý sloupec pak lze kódovat pomocí jedné z těchto technik.
Kódování hodnot